 Une observation sur les documents texte (.txt) montrait que la présence de tableaux ou d’images produisait d’une part, du bruit et d’autre part une légère baisse de reconnaissance de caractère dans le document par tesseract.
Une observation sur les documents texte (.txt) montrait que la présence de tableaux ou d’images produisait d’une part, du bruit et d’autre part une légère baisse de reconnaissance de caractère dans le document par tesseract.
Une étude a donc été poussée afin d’améliorer les océrisations de documents images et deux grands points ont été réalisés à l’heure actuelle :
- L’extraction de tableaux
- Le prétraitement des images
Le prétraitement des images
Les documents pdf à océriser sont des documents contenant des images provenant de scanner et ne sont donc pas forcément de qualité. Ajouter des prétraitements aux images va pouvoir améliorer la reconnaissance de caractère en rendant ceux-ci plus lisibles et plus nettes. Prenons cette image en entrée par exemple :

L’océrisation de ce document va produire un résultat assez médiocre:
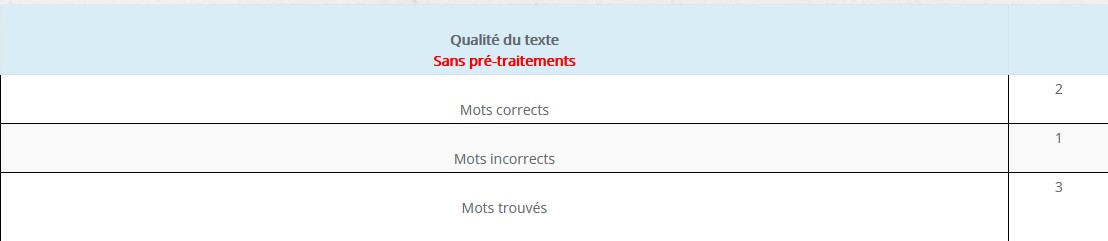
Un ensemble de traitements comme une correction de gamma et des contrastes plus forts vont avoir pour effet de faire ressortir le texte comme ceci:

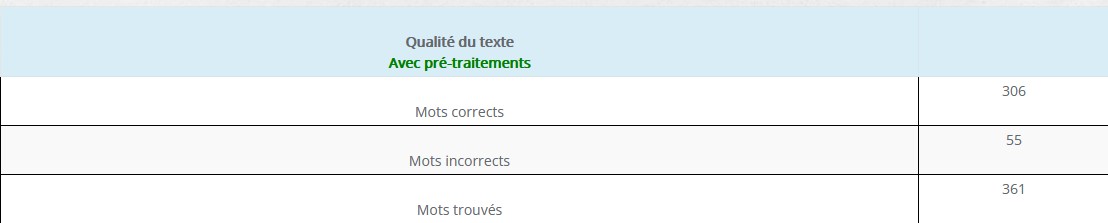
Cette fois ci le document va pouvoir être océrisé de façon optimale :
[table “8” not found /]
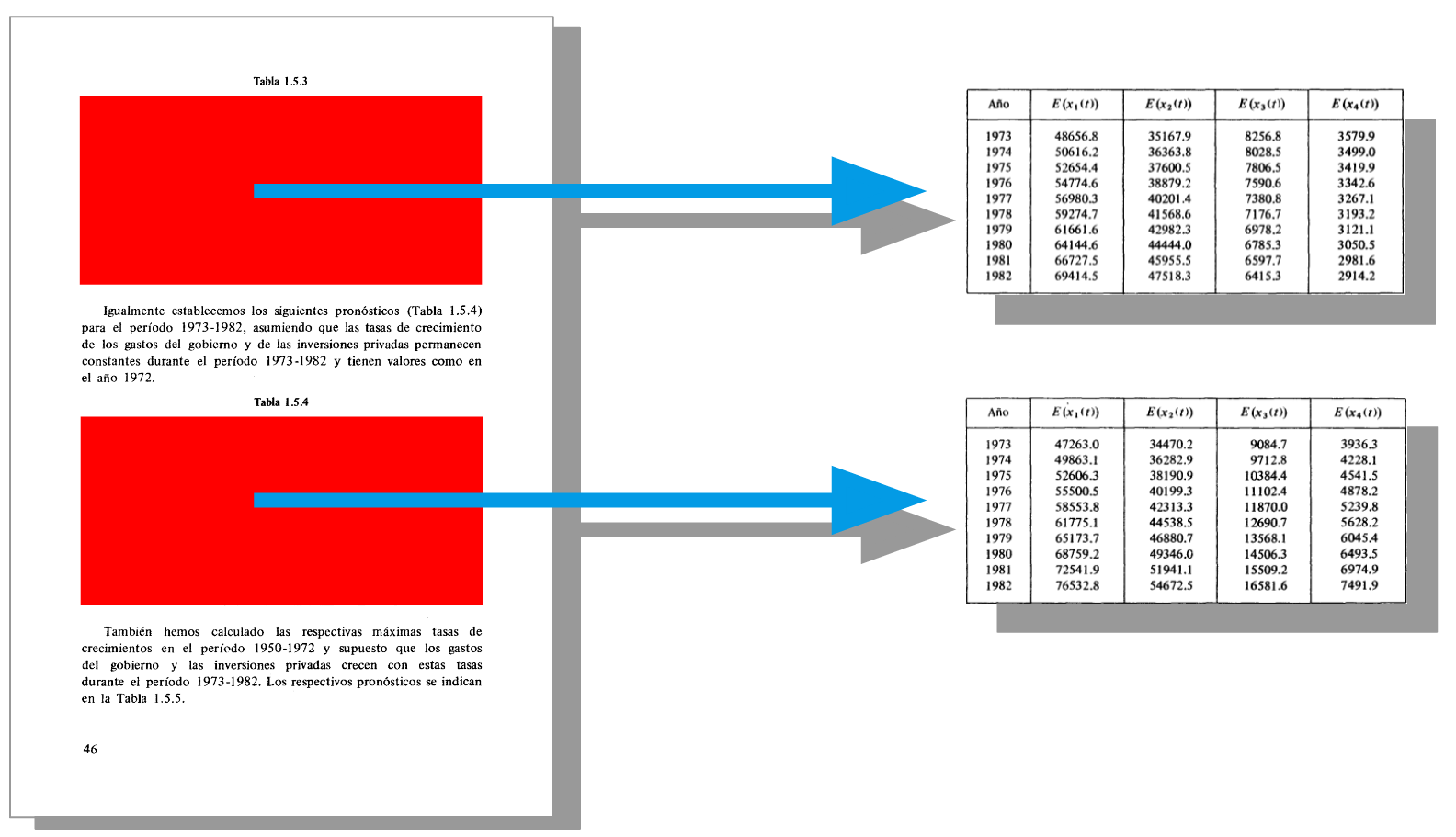
L’extraction des tableaux
L’extraction va permettre d’améliorer visuellement les fichiers textuels et apporter un enrichissement des données en mettant en annexe ceux-ci sans les détruire.
Pour cela un nouveau module à été développé :
Github : https://github.com/Inist-CNRS/pdf-figure-extractor
Npm : https://www.npmjs.com/package/pdf-figure-extractor
Il permet l’extraction de figures comportant un quadrillage tel que les tableaux mais aussi les graphiques.
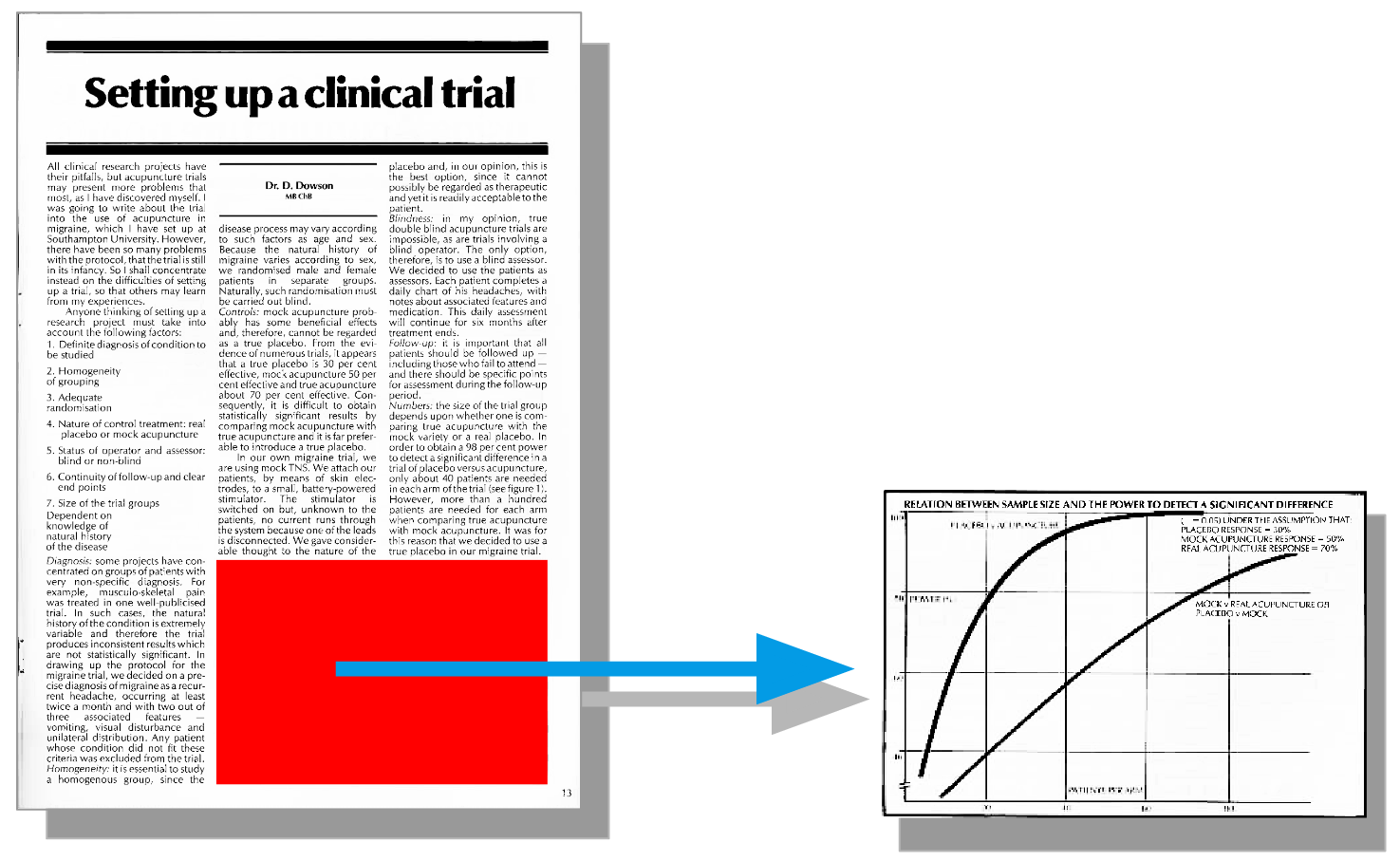
Les outils
Pour ce faire, différents outils ont été utilisés tels qu’openCV ou l’API C++ de Tesseract.
OpenCV est une librairie C++ de détection de forme, elle permet notamment de récupérer les formes étant des rectangles permettant potentiellement de détecter un tableau qui en est constitué.
Tesseract quant à lui est utilisé pour récupérer les parties de documents non océrisables comme les lignes de tableaux, les images etc…
C’est la corrélation des données des deux outils qui permettent de déterminer les éléments à extraire.
Perspectives
Une évolution de ce module pourrait prévoir une détection de différents types de figure. La mise en production sera donc soumise à d’éventuelles évolutions et tests sur les différents corpus.

Besoin d'aide ?
Consultez notre Faq, la documentation Istex ou nos tutoriels
N’hésitez pas à nous contacter si besoin, nous reviendrons rapidement vers vous !
Écrivez-nous
