Bonjour,
L’équipe ISTEX-DATA entame le Sprint #8: « Docteur Levenshtein ». Il a commencé vendredi 25 mars par sa planification et se terminera le 12 mai 2016 par sa revue de sprint. Voici la répartition de la charge de travail par thématique de travail, en fonction des points de complexité attribués par les membres de l’équipe :
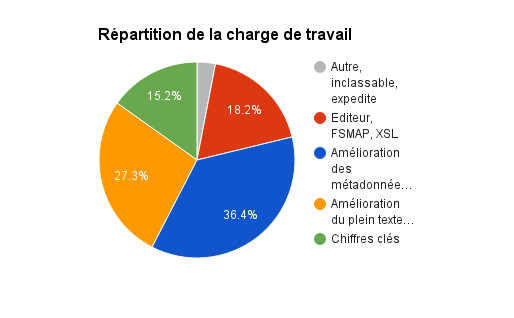 Dans la thématique « Editeur, FSMAP, XSL« , nous allons tout d’abord analyser pourquoi la proportion de full text est supérieur à celle des Refbib sur RSC 1847-2001.
Dans la thématique « Editeur, FSMAP, XSL« , nous allons tout d’abord analyser pourquoi la proportion de full text est supérieur à celle des Refbib sur RSC 1847-2001.
Il faudra au cours de ce sprint obtenir une maîtrise et un contrôle de FSMAP comme par exemple ajouter une confirmation avant le lancement de FSMAP qui aboutira à une mise à jour de la procédure. Pour rappel FSMAP est l’outil qui nous aide à l’analyser quantitative puis qualitative des livraisons de corpus éditeurs.
Dans la thématique « Amélioration des métadonnées (ex: hub, type de doc …) », suite aux observations des anomalies que nous avons faite au sprint dernier, nous allons faire une étude plus approfondie sur ces dates de publication ‘erronées’ (ex. : pour le corpus EEBO avec l’année 0000….) ce qui impliquera une requête API pour une extraction ciblée des documents erronés.
Par ailleurs, nous allons aussi réaliser une étude pour identifier les pistes de correction liées à la constitution des états de collection (top-down & bottom-up). Quand le Publisher-id sera indexé pour tous les corpus, nous pourrons vérifier si le code journal est renseigné pour les documents. Le code journal serait ainsi intégré à l’état de collection au même titre que le titre et l’Issn et permettrait une meilleure identification des publications.
Dans la thématique « Amélioration du plein texte (réOCRisation, restructuration, redressement) », nous allons travailler sur la mise en production de la chaîne d’OCrisation. Pour cela nous allons installer les modules OCR dans la chaîne d’ingestion LoadISTEX. Un test de monté en charge sera réalisé sur le corpus Brill Hacco qui contient environ 11 000 documents. Parallèlement, un état de l’art des méthodes d’évaluation de la qualité de l’OCR s’impose car il faudra ensuite clarifier la méthode d’évaluation de la qualité du résultat de l’OCR.
D’autre part, nous allons identifier un corpus avec un mauvais OCR éditeur, probablement les 13 documents qui composent le corpus gold utilisé lors des premiers test dans le choix de l’outil d’OCRisation. Un des objectifs est de vérifier si par cette réOCRisation on peut augmenter la qualité de détection des RefBib d’un PDF (mal OCRisé par un éditeur) pour par exemple augmenter le nombre de RefBib potentiellement cliquables dans un PDF (possible après un passage par l’OpenURL de l’API ISTEX). Ces documents passeront dans Tesseract et devront être en sortie dans le format PDF. Les PDF éditeur et ces PDF réocérisés passeront dans l’interface web de Grobid pour finalement tester si la détection des RefBib se trouve améliorée.
Dans la thématique « Chiffres clés« , nous allons produire un histogramme sur les dates de publication qui mettra en évidence les différents périodes couvertes par les corpus éditeurs. Pour cela, nous ferons une requête dans API puis un paramétrage de l’outil ezvis pour les mettre en valeur visuellement sur https://data.istex.fr
N’hésitez pas à nous poser vos questions via la liste data-users@listes.istex.fr, ou dans les commentaires du blog.
Bonne fin de journée
Cordialement,
L’équipe ISTEX-DATA

Besoin d'aide ?
Consultez notre Faq, la documentation Istex ou nos tutoriels
N’hésitez pas à nous contacter si besoin, nous reviendrons rapidement vers vous !
Écrivez-nous
